Backups
- Configuring Backups
- Volume Snapshots
- Barman Object Stores
- AWS S3
- Microsoft Azure Blob Storage
- Google Cloud Storage
- Creating a Backup
- Automatic Backups
- Deleting a Backup
- Bootstrapping From a Backup
|
Note
|
Commercial Feature
A commercial Vaadin subscription is required to use Backups in your project. |
Control Center manages databases using CloudNativePG, an open-source Kubernetes operator to manage PostgreSQL on any supported Kubernetes cluster. PostgreSQL natively provides backup and recovery capabilities based on file system level (physical) copy. This means that backups are done by copying the files that PostgreSQL uses to store the data in the database.
In CloudNativePG, the backup infrastructure for each PostgreSQL cluster is made up of the following resources:
-
Write-Ahead Log (WAL) files archive: a location containing the WAL files (transactional logs) that are continuously written by PostgreSQL and archived for data durability
-
Physical base backups: a copy of all the files that PostgreSQL uses to store the data in the database (primarily the
PGDATAdirectory and any tablespaces)
CloudNativePG supports two ways to store physical base backups:
-
on object stores, as tarballs - optionally compressed
-
on Kubernetes Volume Snapshots, if supported by the underlying storage class
Backups are done at the cluster level, not at the database level. This means that you cannot backup a single database at a time using Control Center. Each backup includes all data of all databases in the cluster. Keycloak’s data (all users, roles, etc.), and all data from databases of deployed applications are included in backups.
Configuring Backups
|
Important
| Backups are configured during installation of Control Center. |
Enable backups by setting the postgres.backups.enabled value to true when installing Control Center.
Enabling backups does nothing by itself.
You must also select a backup method and provide proper configuration for the selected method, as well as creating a Kubernetes secret with a valid Vaadin commercial license key.
The available methods for backups are:
To decide which method to use, it is recommended to read CloudNativePG’s official documentation.
Create License Secret
Since backups are a commercial feature, you must provide a valid Vaadin commercial license key to enable the feature.
Refer to the licenses section to find out more about Vaadin commercial licenses.
Vaadin license key files are stored by default in the .vaadin directory under your user’s default directory.
You can create a secret named vaadin-license (or any lowercase RFC1123 subdomain name is valid) that holds the license key with a key that must be named license-key by running:
Source code
shell
kubectl -n <control_center_namespace> create secret vaadin-license --from-file=license-key=/path/to/keyFileOnce the secret is created, you must refer to it during installation by setting the licenseKeySecret value to the name of the secret.
Source code
shell
helm install control-center [...] --set licenseKeySecret=vaadin-licenseHot or Cold Backups
Hot backups refer to those with the possibility to take physical base backups from any instance in the PostgreSQL cluster (either primary or standby) without shutting down the server; they are also known as online backups. They require the presence of a WAL archive. WAL archives are only supported in barman object stores. You can configure hot backups with the volume snapshots method if you also configure a barman object store for the WAL archives.
Cold backups, also known as offline backups, are instead physical base backups taken when the PostgreSQL instance (standby or primary) is shut down. They are consistent per definition and they represent a snapshot of the database at the time it was shut down. As a result, PostgreSQL instances can be restarted from a cold backup without the need of a WAL archive. However, though they can take advantage of the WAL archive, if it is available (with all the benefits on the recovery side highlighted in the previous section). In those situations with a higher Recovery Point Objective (RPO) (for example, 1 hour or 24 hours), and shorter retention periods, cold backups represent a viable option to be considered for your disaster recovery plans.
Volume Snapshots
Volume snapshots provide Kubernetes users with a standardized way to copy a volume’s contents at a particular point in time without creating an entirely new volume. This functionality enables, for example, database administrators to backup databases before performing edit or delete modifications.
A volume snapshot class must be defined in the Control Center configuration for volume snapshots backups to work.
A storage class can also be defined, but you can also work with the default storage class.
You can read more about volume snapshots in the official Kubernetes documentation.
Source code
Example values.yaml file for volume snapshot backups
user:
email: example@vaadin.com
app:
host: cc.mydomain.com
domain: mydomain.com
postgres:
storage:
storageClass: @STORAGE_CLASS # (optional) needed for volume snapshot backups
volumeSnapshotClass: @SNAPSHOT_CLASS # needed for volume snapshot backups
backup:
enabled: true
method: volumeSnapshotSource code
shell
helm install control-center oci://docker.io/vaadin/control-center -n control-center --values="/path/to/values.yaml"|
Note
|
Refer to your cluster provider’s documentation for the name of the volume snapshot class (and storage class) you need to use when replacing @SNAPSHOT_CLASS (and @STORAGE_CLASS)
|
Barman Object Stores
The backup configuration using a cloud object store depends on which cloud object store is used. CouldNativePG’s official documentation lists common object stores and how to configure them. Example configurations are provided below for Microsoft Azure Blob Storage, Google Cloud Storage, Amazon Web Services (AWS) S3, and other S3 compatible object stores. Control Center doesn’t currently support IAM Role for Service Account (IRSA) authentication method or MinIO gateways.
AWS S3
Create a Kubernetes secret containing the credentials needed to authenticate to the object store, with permissions to upload files into the bucket. You will need the following information about the object store:
-
ACCESS_KEY_ID: the ID of the access key that will be used to upload files into S3 -
ACCESS_SECRET_KEY: the secret part of the access key mentioned above
|
Warning
|
To prevent the sensitive values of the secrets being stored in the terminal command history, write down the values in files (without an extra newline character at the end of the text) and pass those files to kubectl to save their content as the secret’s values.
|
Source code
Create secret for AWS S3 credentials
kubectl create secret generic aws-creds \
--from-file=ACCESS_KEY_ID=/path/to/access_key_id_file.txt \
--from-file=ACCESS_SECRET_KEY=/path/to/access_secret_key_file.txtOnce the secret is created, its values can be referred to in the backup configuration when installing Control Center:
Source code
Example values.yaml for barman object store backups on AWS S3
user:
email: example@vaadin.com
app:
host: cc.mydomain.com
domain: mydomain.com
postgres:
backup:
enabled: true
method: barmanObjectStore
barmanObjectStore:
destinationPath: "<destination path here>"
s3Credentials:
accessKeyId:
name: aws-creds # secret name
key: ACCESS_KEY_ID # key in secret
secretAccessKey:
name: aws-creds # secret name
key: ACCESS_SECRET_KEY # key in secretThe destination path can be any URL pointing to a folder where the instance can upload the WAL files, e.g. s3://BUCKET_NAME/path/to/folder.
S3 Compatible Buckets
In case you’re using an S3-compatible object storage, like MinIO or Linode Object Storage, you can specify an endpoint instead of using the default S3 one.
In this example, it will use the bucket of Linode in the region us-east1.
Source code
Example AWS S3 configuration
[...]
postgres:
backup:
enabled: true
method: barmanObjectStore
barmanObjectStore:
destinationPath: "s3://bucket/"
endpointURL: "https://us-east1.linodeobjects.com"
s3Credentials:
[...]In case you’re using Digital Ocean Spaces, you will have to use the path-style syntax.
In this example, it will use the bucket from Digital Ocean Spaces in the region SF03.
Source code
Example S3 compatible bucket configuration
[...]
postgres:
backup:
enabled: true
method: barmanObjectStore
barmanObjectStore:
destinationPath: "s3://[your-bucket-name]/[your-backup-folder]"
endpointURL: "https://sfo3.digitaloceanspaces.com"
s3Credentials:
[...]Microsoft Azure Blob Storage
Azure Blob Storage is the object storage service provided by Microsoft.
In order to access your storage account for backup and recovery of CloudNativePG managed databases, you will need one of the following combinations of credentials:
-
Storage account name and Storage account access key
-
Storage account name and Storage account shared access signature (SAS) Token
-
Storage account name and a properly configured Azure AD Workload Identity.
When using either Storage account access key or Storage account SAS Token, the credentials need to be stored inside a Kubernetes Secret, adding data entries only when needed. The following command performs that:
|
Warning
|
To prevent the sensitive values of the secrets being stored in the terminal command history, write down the values in files (without an extra newline character at the end of the text) and pass those files to kubectl to save their content as the secret’s values.
|
Source code
Create secret for Azure credentials
kubectl create secret generic azure-creds \
--from-file=AZURE_STORAGE_ACCOUNT=/path/to/storage_account_name.txt \
--from-file=AZURE_STORAGE_KEY=/path/to/storage_account_key.txt \
--from-file=AZURE_STORAGE_SAS_TOKEN=/path/to/sas_token.txt \
--from-file=AZURE_STORAGE_CONNECTION_STRING=/path/to/connection_string.txtGiven the previous secret, the provided credentials can be injected inside the cluster configuration:
Source code
Example Microsoft Azure Blob Storage backup configuration
[...]
postgres:
backup:
enabled: true
method: barmanObjectStore
barmanObjectStore:
destinationPath: "<destination path here>"
azureCredentials:
connectionString:
name: azure-creds
key: AZURE_CONNECTION_STRING
storageAccount:
name: azure-creds
key: AZURE_STORAGE_ACCOUNT
storageKey:
name: azure-creds
key: AZURE_STORAGE_KEY
storageSasToken:
name: azure-creds
key: AZURE_STORAGE_SAS_TOKEN
[...]When using the Azure Blob Storage, the destinationPath fulfills the following structure:
<http|https>://<account-name>.<service-name>.core.windows.net/<resource-path>
where <resource-path> is <container>/<blob>. The account name, which is also called storage account name, is included in the used host name.
Other Azure Blob Storage Compatible Providers
If you are using a different implementation of the Azure Blob Storage APIs, the destinationPath will have the following structure:
<http|https>://<local-machine-address>:<port>/<account-name>/<resource-path>
In that case, <account-name> is the first component of the path.
This is required if you are testing the Azure support via the Azure Storage Emulator or Azurite.
Google Cloud Storage
Currently, Control Center supports only one of two authentication methods for Google Cloud Storage.
Following the instruction from Google you will get a JSON file that contains all the required information to authenticate.
The content of the JSON file must be provided using a Secret that can be created with the following command:
Source code
Create secret for Google Cloud credentials
kubectl create secret generic backup-creds --from-file=gcsCredentials=gcs_credentials_file.jsonThis creates the Secret with the name backup-creds to be used in the YAML file like this:
Source code
Example Google Cloud Storage backup configuration
[...]
postgres:
backup:
enabled: true
method: barmanObjectStore
barmanObjectStore:
destinationPath: "gs://<destination path here>"
googleCredentials:
applicationCredentials:
name: backup-creds # secret name
key: gsCredentials # key of value in secret
[...]Now the operator will use the credentials to authenticate against Google Cloud Storage.
|
Warning
| This method of authentication will create a JSON file inside the container with all the needed information to access your Google Cloud Storage bucket, meaning that if someone gets access to the pod they will also have write permissions to the bucket. |
Creating a Backup
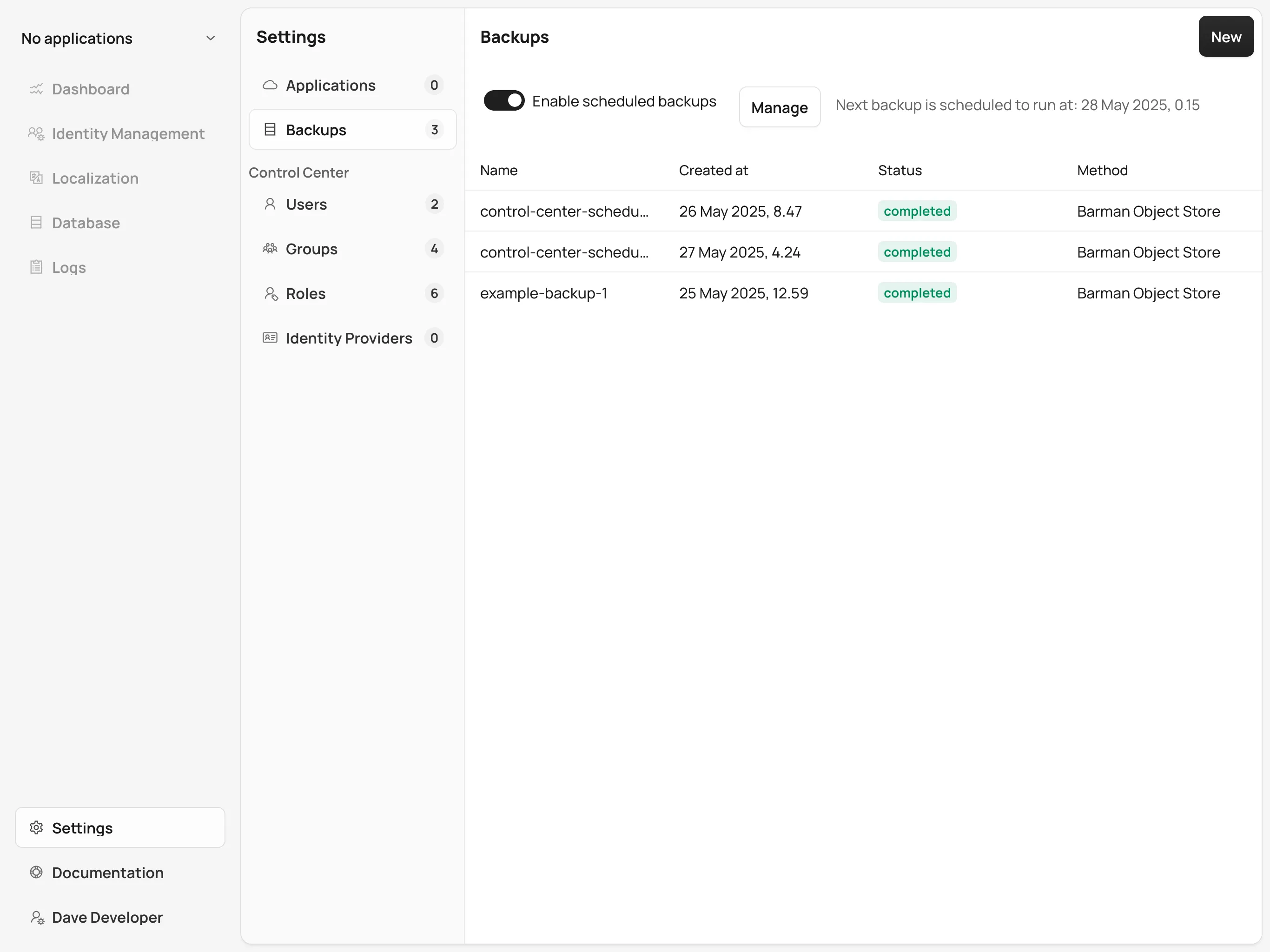
You can see the list of backups, create a new backup, and delete backups from the Backups screen in the Settings section of Control Center.
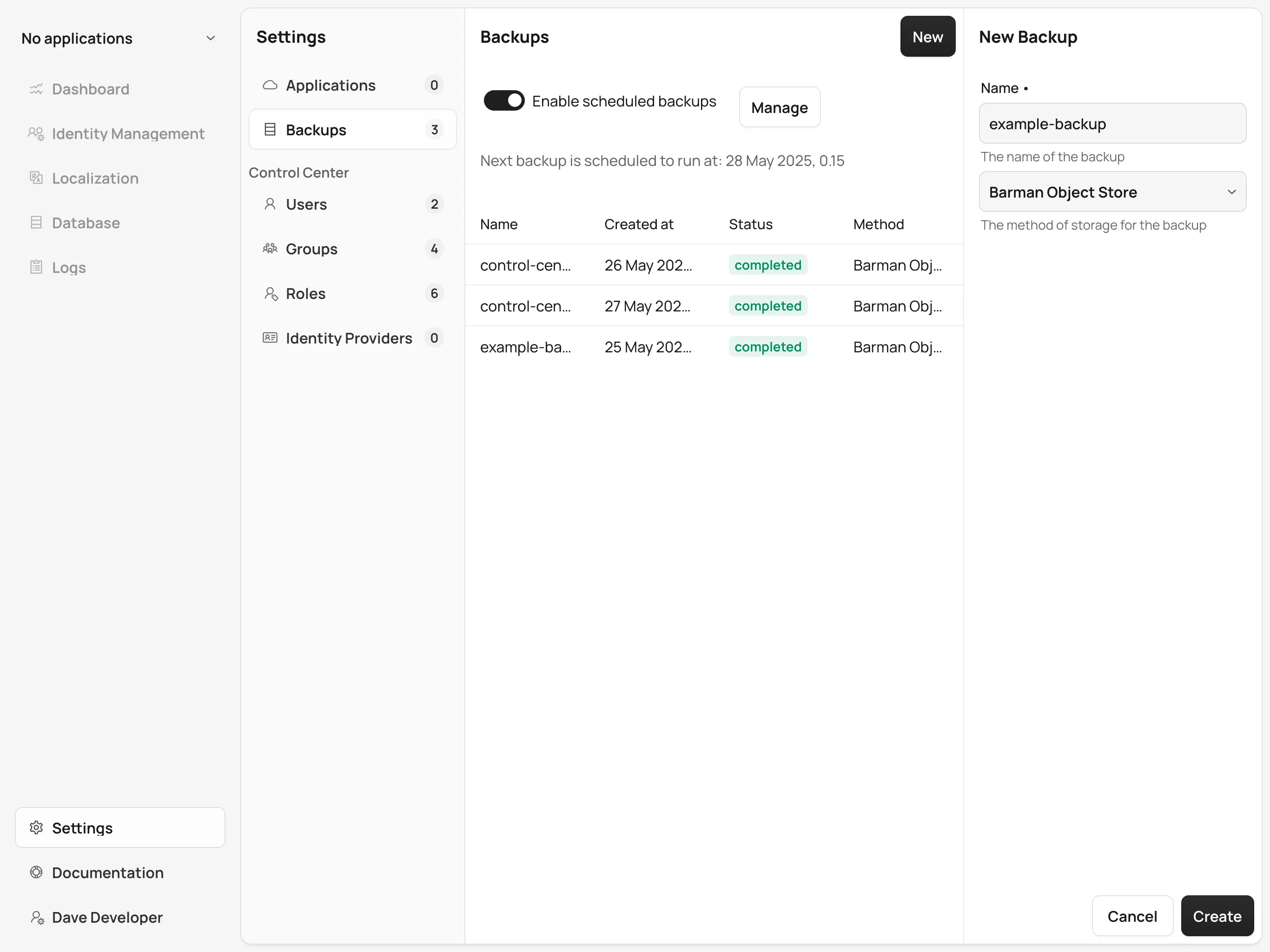
To create a new backup, click on the New button on the top right corner of the screen.
In the right-hand panel, write a name for the backup in the Name field.
The name must not contain spaces, uppercase letters or any special characters other than dash -.
Select a backup method using the Method select component.
Your Control Center installation must be configured to support the selected backup method.
Click the Create button at the bottom of the panel and the backup is created.
The status of the backup is shown in the table.
Automatic Backups
It is possible to schedule backups to happen automatically at regular intervals. The options let you schedule backups so they happen either once every week, once every day, or once every hour. The scheduled automatic backups can be toggled on or off using the switch at the top of the Backups screen.
To choose the schedule, click on the Manage button. It opens a dialog with controls that let you choose the frequency in which the automatic backups are run as well as extra controls to choose the specific time when they should run. Select a desired schedule and click Save.
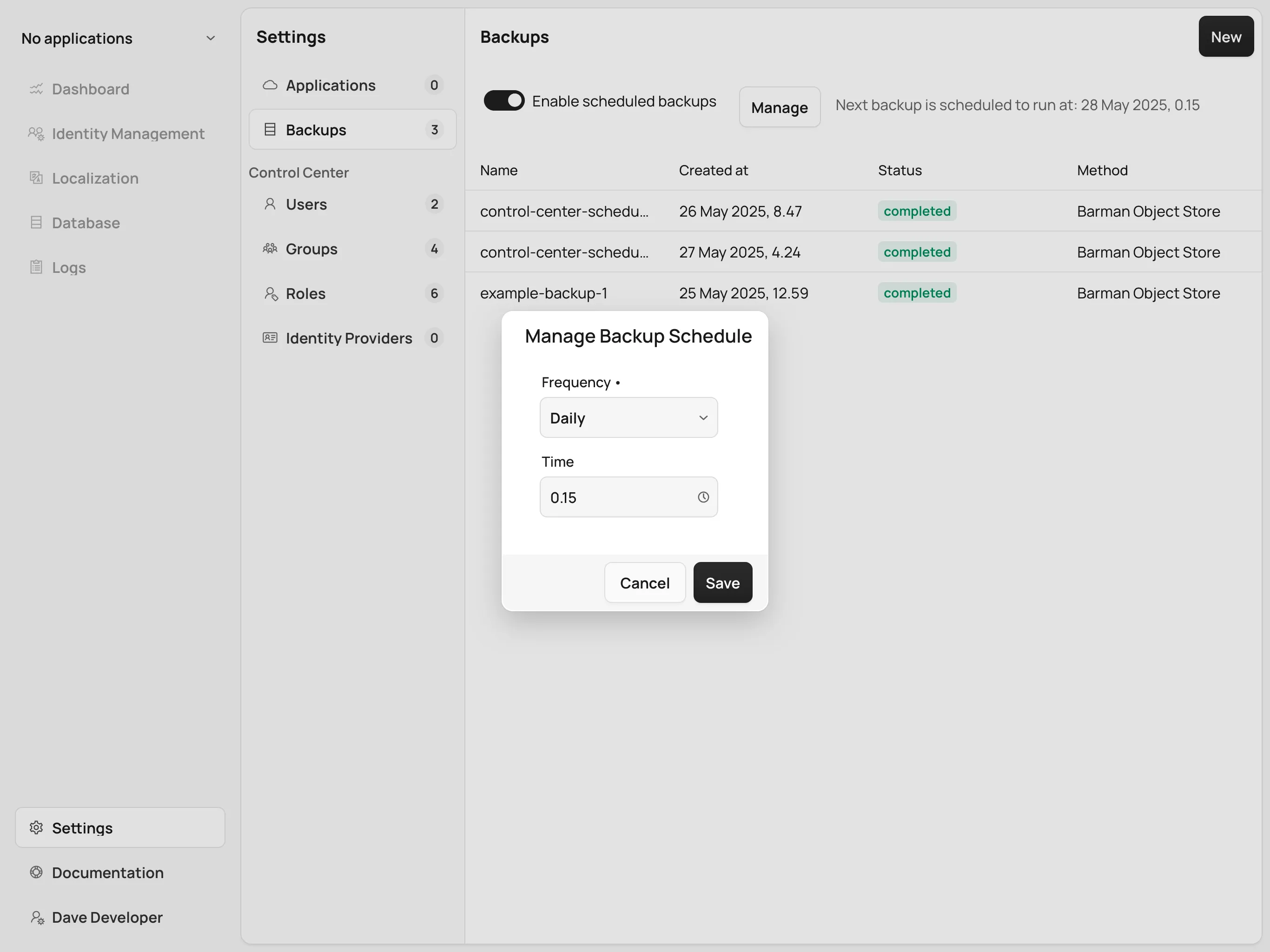
Whatever the current schedule may be, the time when the next automatic backup is set to run is shown at the top of the Backups screen, so long as automatic backups are enabled. To enable or disable automatic backups, click on the switch at the top of the Backups screen.
Deleting a Backup
To delete a backup, select it from the grid so the right-hand panel opens with its information. Click on the Delete button at the bottom of the right-hand panel to show a confirmation dialog. Confirm you want to delete the backup by clicking Confirm and the backup resource is deleted from your Kubernetes cluster. This, however, does not delete the backup data in the underlying storage method. To delete the actual backup data, you must delete the volume snapshot used by it (for volume snapshot backups) or the files from the cloud storage (for barman object store backups).
Bootstrapping From a Backup
Recovery refers to the process of starting a new installation of Control Center using an existing backup. You cannot perform recovery in place on an existing installation. Recovery is instead a way to bootstrap a new Control Center cluster starting from an available physical backup. This is a limitation of CloudNativePG.
To start a new installation from a backup, you must set the postgres.restoreFromBackup value with the name of the backup as shown in the list of backups as its value.
Run helm install command as usual, using the aforementioned value and the new installation will have all the data stored in the backup, including Keycloak users and configuration, and any and all deployed application’s databases.
Source code
Recovery configuration example
[...]
postgres:
restoreFromBackup: example-backup
[...]