What do we want to achieve?
In the last part of this series, we have seen how a minimal approach can be implemented using observer pattern. In doing so, it became clear that something needs to be done in the implementation, in order to remove the restrictions of the first version. The JDK itself offers a very convenient implementation since Java 8. We will now have a look at exactly this.
In addition to the source text examples given in this article, I will also use the sources from the Open Source project
Functional-Reactive http://www.functional-reactive.org/. The sources are available at https://github.com/functional-reactive/functional-reactive-lib
Process, Thread, Fiber, ..
There are lot of things, using which it becomes possible for a developer to let the workflows run in a competitive way. These possibilities have different isolation stages and resources, which are used while doing this. At the level of the operating system, for instance, we are in a position to outsource different things to different processes. Within the application, there is the thread, by means of which the program or the runtime environment can distribute things to different processors. I am omitting at this point that there are different mappings and assume, to simplify things, that one thread is mapped to one operating system thread. However, there is something else here, which is easier. The term Fiber is used here. If you wish to know more about the definitions, please read the following material at Wikipedia. https://de.wikipedia.org/wiki/User-Thread At this point, I do not want to go in the details of the differences, but instead formulate the basic idea that a fiber is something smaller than a thread. In simple words, a thread can process several fibers.
We will now have a closer look at the CompletableFuture. As a simplification, I will assume that a CompletableFuture can be localized at the level of a fiber. This means that we have a pool of threads, which is used to process an arbitrary set of tasks by means of CompletableFuture.
The task
As an example, it is assumed at this point that two values must be taken from different sources and processed using an operator to give a result. This result and one more value from a third source is processed using another operator to give a final result.
It is important here that the sources respond with different time periods. This means that one always has to wait for one of the respective input values. The probability of both the values being available at the same time is very low.
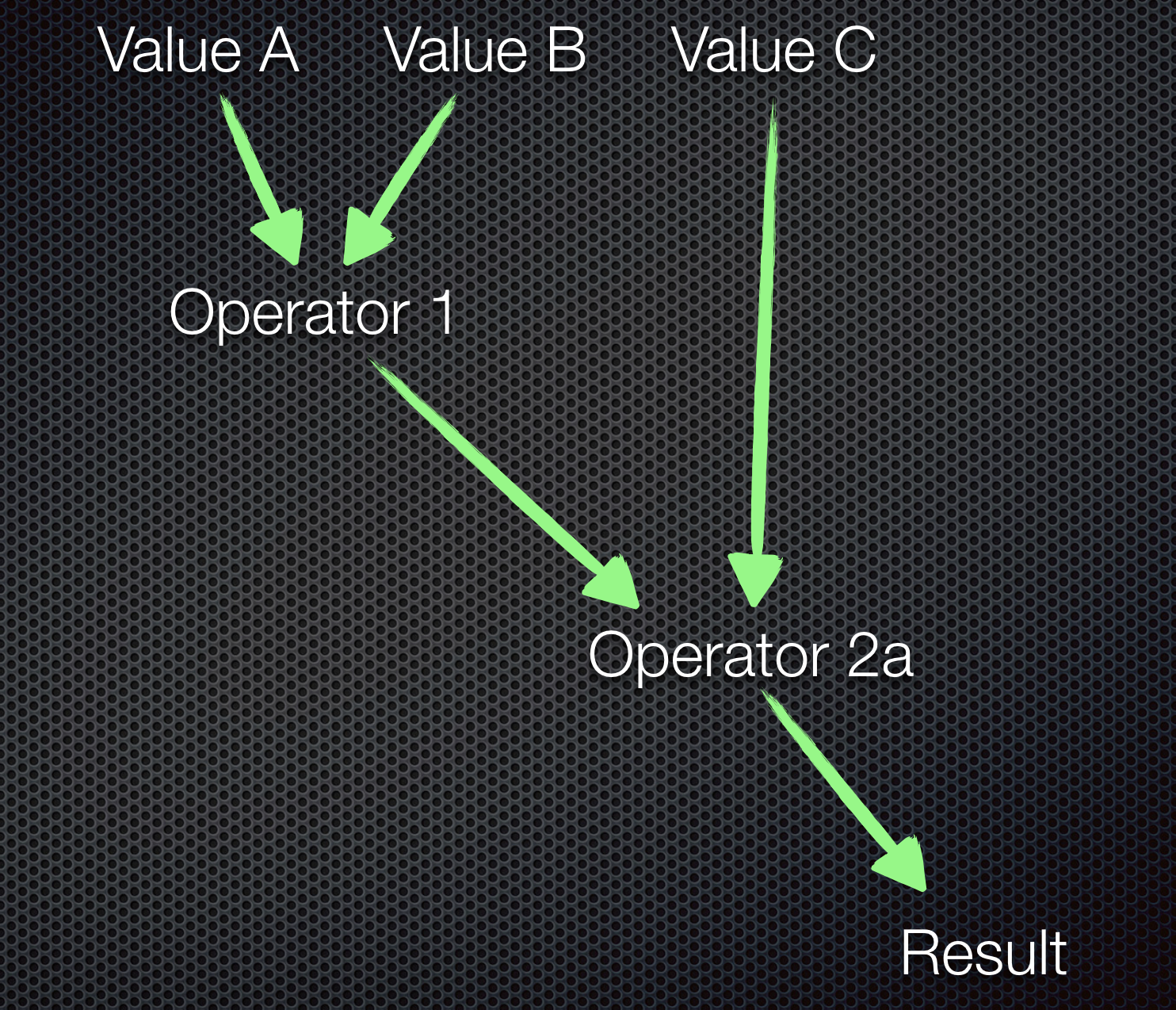
It can easily be imagined that blocking calls can be caused here. We now want to avoid this in a reactive manner. How can we map this by means of CompletableFuture?
CompletableFuture - The beginning
The class CompletableFuture principally provides one with two ways of formulating a task. In doing so, one differentiates between two cases. In the first case, the task returns a result and in the second no result is returned.
Tasks that do not return a result are formulated by means of Runnable. This interface is already known from the classical Java programming with threads. Since this is a FunctionalInterface, one can take the help of lambdas for formulation.
final CompletableFuture<Void> cfRunnableA = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
System.out.println("Hello reactive World");
}
});
final CompletableFuture<Void> cfRunnableB = CompletableFuture
.runAsync(() -> System.out.println("Hello reactive World"));If a result is now expected, one can use the method supplyAsync. Here, a Supplier<T>is specified. The supplier should make it possible forCompletableFutureto request this by means of the specifiedSupplier<T>` at the time, when the value is needed for processing.
final CompletableFuture<String> cfCallableA = CompletableFuture
.supplyAsync(new Supplier<String>() {
@Override
public String get() {
return "Hello reactive World";
}
});
final CompletableFuture<String> cfCallableB = CompletableFuture
.supplyAsync(() -> "Hello reactive World");In the examples just shown, we get an instance of the class CompletableFuture. In the first example, a CompletableFuture<Void> and in the second example a CompletableFuture<String>.
CompletableFuture - The end
With the help of this instance, one can now wait for the processing. There are different possibilities here. The methods shown below are all blocking i.e., the program waits till the result comes or till an exception situation occurs.
join()
One can wait with the method join() till the result becomes available. The method returns the value directly, without possibly packing it again in an Optional<T>. It can naturally also happen here that the wait becomes eternal. As soon as an error occurs in the processing in the form of an exception, this is thrown packed as RuntimeException.
get()
The method get(), which is present in two instances with and without the specification of a timeout, can also wait for the result. Contrary to the method join(), the methods contain two or three exceptions in the signature, (InterruptedException, TimeoutException, ExecutionException)
final CompletableFuture<Void> cfRunnableB = CompletableFuture
.runAsync(() -> System.out.println("Hello reactive World"));
try {
final Void aVoidA = cfRunnableB.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
try {
final Void aVoidB = cfRunnableB.get(1_000 , MILLISECONDS);
} catch (InterruptedException | TimeoutException | ExecutionException e) {
e.printStackTrace();getNow()
If a result is to be fetched at a defined point of time, then the method getNow() can be used. However, an alternative value must always be specified here, since it is not guaranteed that the final value has already been generated. Therefore, this method has no exception in the signature. The developer must decide himself, whether and when these methods can be used.
final CompletableFuture<String> cfCallableB = CompletableFuture
.supplyAsync(() -> "Hello reactive World");
final String now = cfCallableB.getNow("alternative");thenAccept()
However, it is also possible to define what should happen, if the processing has reached this point and waits here for the result without blocking. The return value is an instance of the type CompletableFuture<Void>. To achieve this, a Consumer<T> is specified using the method thenAccept(..), which is supposed to finally process the result generated till this time.
final Supplier<String> task = ()-> "Hello reactive World";
final CompletableFuture<String> cf = CompletableFuture.supplyAsync(task);
final CompletableFuture<Void> acceptA = cf.thenAccept(System.out::println);CompletableFuture - Async and ThreadPools
Now, for instance, there is also the method thenAcccept() in the asynchronous mode and is called as thenAcceptAsync(). This difference by name is often present in the class CompletableFuture and always denotes the asynchronous variant. Another special feature is that this method also has the possibility of specifying a dedicated Executor. In this way, the resource pool available only for this step can be specified explicitly. If this is not so, then always the CommonForkJoinPool is used.
final Supplier<String> task = () -> "Hello reactive World";
final CompletableFuture<String> cf = CompletableFuture.supplyAsync(task);
final CompletableFuture<Void> acceptA = cf.thenAcceptAsync(System.out::println);
final ExecutorService fixedThreadPool = Executors
.newFixedThreadPool(Runtime.getRuntime()
.availableProcessors());
final CompletableFuture<Void> acceptB = cf.thenAcceptAsync(System.out::println, fixedThreadPool);Now the question arises, how one can write all this in a compact way. Luckily, the API is very friendly in this case and we can achieve this aim quite easily with the FluentAPI. Given below are three different possibilities or variants.
final ExecutorService fixedThreadPool = Executors
.newFixedThreadPool(Runtime.getRuntime()
.availableProcessors());
final Supplier<String> task = () -> "Hello reactive World";
final Consumer<String> consumer = System.out::println;
final CompletableFuture<Void> cfA = CompletableFuture
.supplyAsync(task)
.thenAcceptAsync(consumer , fixedThreadPool);
final CompletableFuture<Void> cfB = CompletableFuture
.supplyAsync(() -> "Hello reactive World")
.thenAcceptAsync(System.out::println , fixedThreadPool);
final CompletableFuture<Void> cfC = CompletableFuture
.supplyAsync(() -> "Hello reactive World")
.thenAcceptAsync(System.out::println);Back to the task
We now come back to the task presented in the beginning. A path has to be mapped here, which consists of more than just one work step.
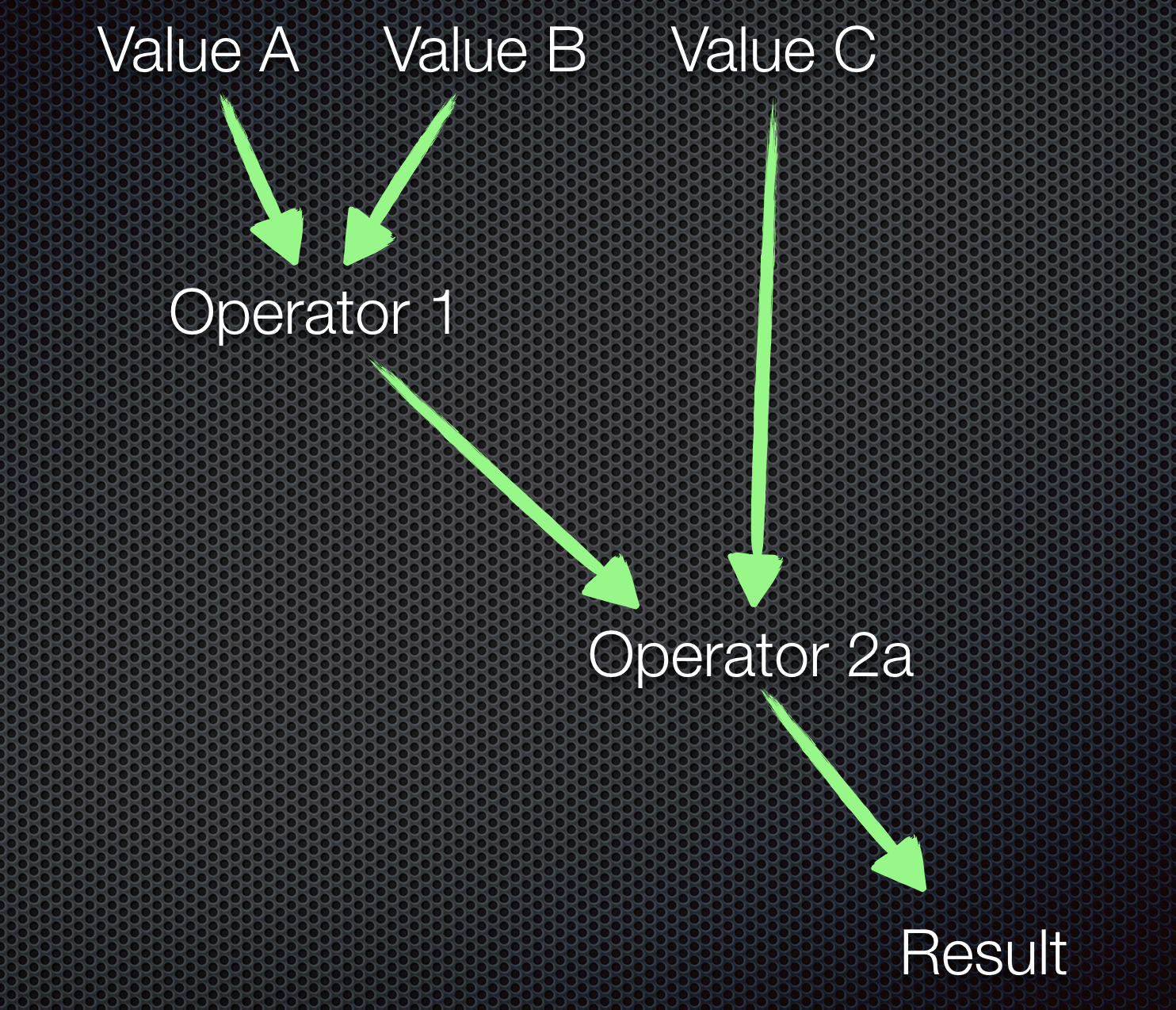
It can be seen here that there are several intermediate results. Each intermediate result can have a different type. The first step in this example is to fetch a value from the source A. The source stands symbolically for a random source i.e., it can be a value from a database, a REST resource or anything else. There is one thing common in all the sources indicated here - the values come with a time delay that cannot be defined exactly.
First of all, we define the three input types for our example. All these have the same structure and consist of a pseudo-value of the type String and an instance of the type LocalDateTime.
public class InputA extends Pair<String, LocalDateTime> {
public InputA(String value , LocalDateTime timeStamp) {
super(value , timeStamp);
}
public String value(){return getT1();}
public LocalDateTime timestamp(){return getT2();}
}
public class InputB extends Pair<String, LocalDateTime> {
public InputB(String value , LocalDateTime timeStamp) {
super(value , timeStamp);
}
public String value(){return getT1();}
public LocalDateTime timestamp(){return getT2();}
}
public class InputC extends Pair<String, LocalDateTime> {
public InputC(String value , LocalDateTime timeStamp) {
super(value , timeStamp);
}
public String value(){return getT1();}
public LocalDateTime timestamp(){return getT2();}
}We now start here with the request to fetch the value from the source A, B and C. No time delays are simulated here and the access to the respective source is implemented in the same way for simplicity.
private static Supplier<InputA> supplierA() {
return () -> {
//some time consuming stuff
final int nextInt = new Random().nextInt(10);
return new InputA(String.valueOf(nextInt) , LocalDateTime.now());
};
}
private static Supplier<InputB> supplierB() {
return () -> {
//some time consuming stuff
final int nextInt = new Random().nextInt(10);
return new InputB(String.valueOf(nextInt) , LocalDateTime.now());
};
}
private static Supplier<InputC> supplierC() {
return () -> {
//some time consuming stuff
final int nextInt = new Random().nextInt(10);
return new InputC(String.valueOf(nextInt) , LocalDateTime.now());
};
}Under the assumption that the respective sources cause delays in the system, the requests are processed in individual resources defined and dimensioned extra for this. Please always note when using in the real system that the dimensioning of the resources cannot represent a trivial problem. These too are shown here in the same way for the sake of simplicity.
private static final int nThreads = Runtime.getRuntime()
.availableProcessors();
private static final ExecutorService poolInputA = Executors
.newFixedThreadPool(nThreads);
private static final ExecutorService poolInputB = Executors
.newFixedThreadPool(nThreads);
private static final ExecutorService poolInputC = Executors
.newFixedThreadPool(nThreads);We now have to map the supplier by technical information, how the data are to be fetched from the source and define the resources intended for this. The next step is now to generate the instances of the type CompletableFuture.
public static CompletableFuture<InputA> sourceA(){
return CompletableFuture.supplyAsync(supplierA(), poolInputA);
}
public static CompletableFuture<InputB> sourceB(){
return CompletableFuture.supplyAsync(supplierB(), poolInputB);
}
public static CompletableFuture<InputC> sourceC(){
return CompletableFuture.supplyAsync(supplierC(), poolInputC);
}Join work steps
At this point now all values can be fetched. The definition of the processing itself now starts. In this case too, the result type can be different in each step, which has been done here for demonstration purposes.
According to this, first of all the definition of the first result types and the definition of the resources to be used.
public static class ResultOne extends Pair<String, LocalDateTime> {
public ResultOne(String value , LocalDateTime timeStamp) {
super(value , timeStamp);
}
public String value() {return getT1();}
public LocalDateTime timestamp() {return getT2();}
}
private static final ExecutorService poolOperatorA = Executors
.newSingleThreadExecutor();So far, everything is already known - only the definition of the operator is missing. Instances of the type CompletableFuture can be combined using the method thenCombine(..) or also asynchronously using the method thenCombineAsync(..). To do this, a BiFunction is needed, which is in a position to process both the result values of the two CompletableFuture involved to make a new result value.
private static BiFunction<InputA, InputB, ResultOne> operatorOne() {
return (a , b) -> {
//for Demo
System.out.println("operatorOne.a = " + a);
System.out.println("operatorOne.b = " + b);
return new ResultOne(a.value() + " + " + b.value() , LocalDateTime.now());
};
}At this point, one can formulate the processing chain as follows.
final CompletableFuture<ResultOne> combineAsync = sourceA()
.thenCombineAsync(sourceB() , operatorOne() , poolOperatorA);We get again an instance of the type CompletableFuture<ResultOne>. One proceeds in a similar way for mapping the last work step. The result type, the operator and the resources to be used are defined.
public static class ResultTwo extends Pair<String, LocalDateTime> {
public ResultTwo(String value , LocalDateTime timeStamp) {
super(value , timeStamp);
}
public String value() {return getT1();}
public LocalDateTime timestamp() {return getT2();}
}
private static final ExecutorService poolOperatorB = Executors
.newSingleThreadExecutor();
private static BiFunction<ResultOne, InputC, ResultTwo> operatorTwo() {
return (a , b) -> {
//for Demo
System.out.println("operatorTwo.a = " + a);
System.out.println("operatorTwo.b = " + b);
return new ResultTwo(a.value() + " - " + b.value() , LocalDateTime.now() );
};
}We now have all the steps together and can formulate the entire workflow.
sourceA()
.thenCombineAsync(sourceB() , operatorOne() , poolOperatorA)
.thenCombineAsync(sourceC() , operatorTwo() , poolOperatorB)
.thenAcceptAsync(System.out::println)
.join();One can notice, in my opinion, very well the fact that the functional aspects match very well with the use of CompletableFuture. Functions define the operators, the technical aspect of dimensioning is extracted in the definition of the resources and the workflow can be formulated in a linear way.
We will now see how this workflow can be used n number of times in parallel.
Multiple Pipelines
The processing starts as soon as an instance of the type CompletableFuture has been generated. Accordingly, the first question now arises how the pipelines can be defined without having to lead them directly in the usage. And how can one comfortably handle a set of these instances.
We now come here to the combination of streams and the CompletableFuture.
The basic idea is quite simple. As soon as we are in a position to define the source, we can use it for generating a stream source. Streams can be generated from this, which either represent infinitely the processing of multiple data sources or process fixed defined work packets.
To maintain clarity, it is assumed here that a fixed quantity of 1000 results has to be generated. To do this, for instance, one can use the IntStream.
IntStream
.range(0,1_000)
.parallel()
.mapToObj(value -> new Pair<>(value , sourceA()
.thenCombineAsync(sourceB() , operatorOne() , poolOperatorA)
.thenCombineAsync(sourceC() , operatorTwo() , poolOperatorB)
.thenAcceptAsync(System.out::println)))
.map(p -> {
final Void join = p.getT2().join();
return p.getT1();
})
.forEach(System.out::println);Summary
In this example, 1000 elements are taken and processed from the respective sources. It now requires a little more effort to implement the same solution by means of threads. The more so as the developer then has to deal with the idioms of the synchronization mechanisms used such as the StampedLock.
Here, a separate resource pool is defined for each stage and also a separate result type. If we now write this a little more compactly, we essentially get fewer lines of source code. In the project there will be simplifications or assumptions, which allow individual elements to be omitted. For instance, one can define only one ThreadPool for waiting for the input values and one for executing the operators. The number of types of the respective intermediate results will possibly be not so many. And some of the operators can be defined right on the spot. Everything together leads to the following example.
private static final int nThreads = Runtime.getRuntime()
.availableProcessors();
private static final ExecutorService poolToWait = Executors
.newFixedThreadPool(nThreads * 10);
private static final ExecutorService poolToWork = Executors
.newFixedThreadPool(nThreads);
private static CompletableFuture<Void> createCF() {
return supplyAsync(() -> valueOf(new Random().nextInt(10)) , poolToWait)
.thenCombineAsync(supplyAsync(() -> valueOf(new Random().nextInt(10)) , poolToWait) ,
(a , b) -> a + " + " + b ,
poolToWork)
.thenCombineAsync(supplyAsync(() -> valueOf(new Random().nextInt(10)) , poolToWait) ,
(a , b) -> a + " - " + b ,
poolToWork)
.thenAcceptAsync(System.out::println);
}
public static void main(String[] args) {
IntStream
.range(0 , 1_000)
.parallel()
.mapToObj(value -> new Pair<>(value , createCF()))
.map(p -> {
p.getT2().join();
return p.getT1();
}
)
.forEach(System.out::println);
poolToWait.shutdown();
poolToWork.shutdown();
}However, one quickly reaches here a point, where the source code to be maintained becomes quite confusing. Accordingly, my personal opinion is to implement a little more detailed version.
In a nutshell, the CompletableFuture is a very powerful and also a very simple tool for implementing reactive aspects in an application.
In the next sections, the elements show here will be extended by the new possibilities provided by Java 9.
You can find the source code at:
https://github.com/Java-Publications/functional-reactive-with-core-java-009.git
If you have questions or comments, simply contact me at sven@vaadin.com or via Twitter @SvenRuppert.
Happy coding!