
I shared my experience with performance optimizations a couple of weeks ago at our Vaadin Create conference. One key takeaway was implementing lazy loading at the client-server and database layers. Lazy loading essentially transfers only the required data to the client and requests a reasonable amount of data at once from the database, minimizing the number of queries.
After my presentation, my heart sank when one of our customers asked: “What about TreeGrid?” This commonly used Vaadin component does a very good job of lazy-loading between the client and the server. However, the current support for efficient backend lazy-loading is pretty much non-existent.
There is no support for paged requests, and the most intuitive API can easily cause separate DB visits for every node. I got triggered by this limitation and implemented a variation of the component called TreeTable (available in the Viritin add-on). It has nearly identical features to TreeGrid, but its data binding uses paged access to the backend. However, that was the easy part; efficiently querying the hierarchical data from a relational database is the more challenging half of the problem.
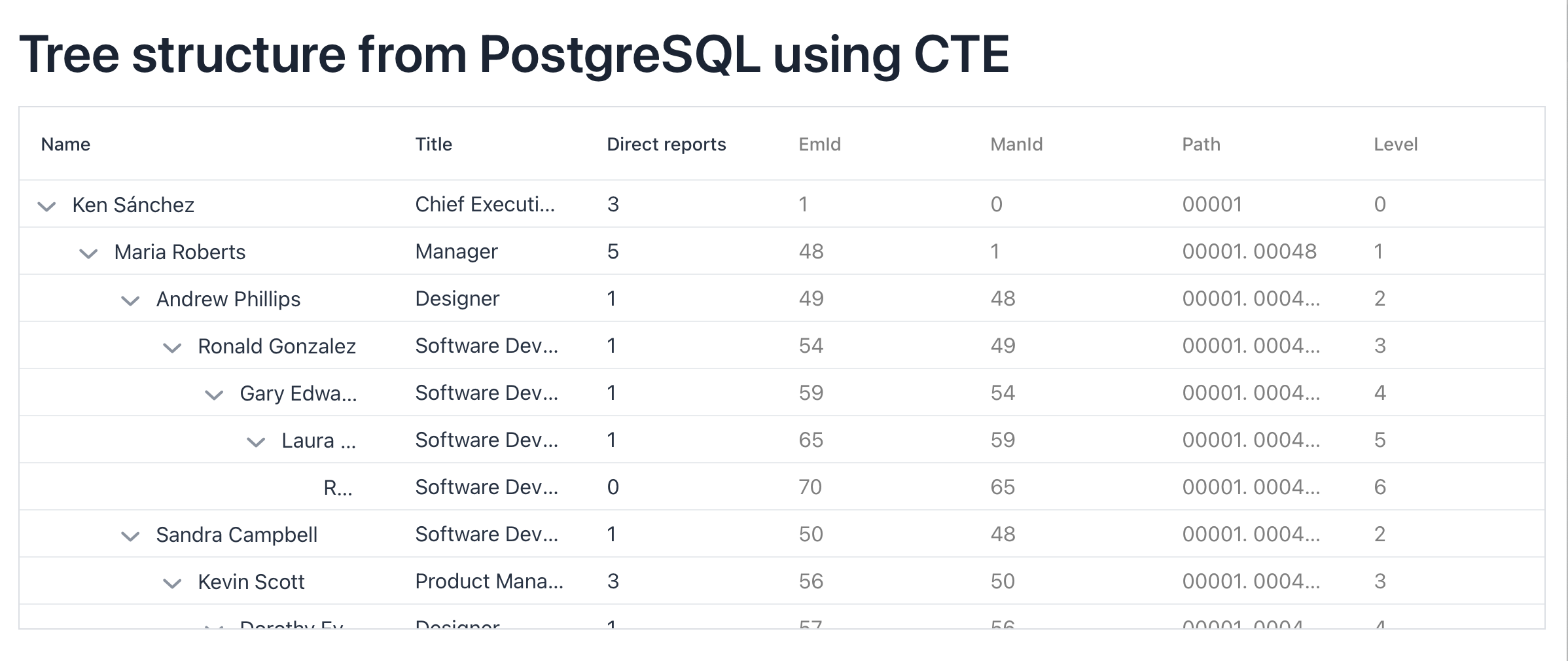 A screenshot of a demo application drawing hierarchical data from a PostgreSQL, using a single-paged SQL query, and visualizing that using a Java UI component.
A screenshot of a demo application drawing hierarchical data from a PostgreSQL, using a single-paged SQL query, and visualizing that using a Java UI component.
While working on real-world-like tests for the TreeTable add-on component, I experimented with various approaches. I remember struggling with the same problem in my earlier life (over two decades ago) when trying to minimize query counts for a LAMP stack web application. Achieving a single SQL query with a properly normalized database was nearly impossible back then. The flashback continued as I recalled an eye-opening moment at Nokia, where a database engineer effortlessly solved the same problem in less than a minute using a magical CONNECT BY query available in the Oracle database.
Let’s examine three different methods for efficiently storing and retrieving hierarchical data from a relational database and for connecting relational data to a Java UI component.
1. Standard SQL and Common Table Expressions
Databases, although often considered constants in our industry, have evolved. Most widely used RDBMS systems now support a standardized SQL feature called Common Table Expressions (CTEs). CTEs essentially create a temporary table within the query, allowing us to recursively fetch rows and construct the hierarchy in proper order with adequate metadata.
Although the hierarchical CTE queries can be challenging, the good thing is that the DB structure remains as simple as possible. In my demo application, I’m using an employee table based on examples from SQL Server:
CREATE TABLE employees
(
employeeId serial PRIMARY KEY,
firstName varchar(30) NOT NULL,
lastName varchar(40) NOT NULL,
title varchar(50) NOT NULL,
managerId int NULL,
FOREIGN KEY (managerId)
REFERENCES employees (employeeId)
);To simplify handling the results in the UI, I’m using the following simple DTO, which I map from the JDBC result set (technically using Spring’s JDBC template). While the table could easily map to a JPA entity, you will need additional details from the database for UI presentation.
So, if you use JPA to edit or persist your data, you’ll most likely need a separate DTO and native SQL query (update: or Hibernate's non-standard JPQL feature). In addition to the DB columns, a “level” field is required to visualize the hierarchy in the TreeTable. The path will show the full parent path to the root. I’m taking that to the DTO (and UI) to make it easier to understand this example, but in the query, I use it to sort the results in a meaningful order. The directReports field, which counts the number of subordinates, is just an example column showcasing additional data queried from the DB.
public class DirectReportsDto {
// Actual DB columns:
private final Integer managerId;
private final Integer employeeId;
private final String title;
private final String firstName;
private final String lastName;
// Calculated columns:
private final Integer directReports;
private final Integer level;
private final String path;
// Getters/setters omitted…
}The part of this approach that needs the most explanation is the CTE magic within the SQL query. You can check the complete example from the EmployeeService class, but it is so long that it doesn’t fit into this blog post. 🙂 To explain recursive CTE queries, I’ve derived this minimal example from the PostgreSQL manual.
-- Part I : Define the “result table”
WITH RECURSIVE t(n, level) AS (
-- Part II: query for root(s)
VALUES (1, 0)
UNION ALL
-- Part III: Recursive query, that can refer the parent
SELECT n+1, level+1 FROM t WHERE n < 10
)
-– Part IV: The “actual query” from the “temporary table”
SELECT CONCAT( LPAD('', level, '-'), n) FROM t;The recursive CTE query has four logical parts:
- Defining the temporary table: In this example, it’s named ‘t’ and comprises two columns: ‘n’ and ‘level.’
- Selecting the rows where the recursion begins: In this case, it starts with a row having ‘n’ as 1 and ‘level’ as 0.
- Selecting the rows processed by recursive queries: Here, referring to the parent rows/nodes is possible. In this example, the ‘n’ and ‘level’ columns are incremented, while the ‘n’ in the parent row is less than 10.
- Executing the final query from the “temporary table”: In this example, the resulting set is a single column with integers from 1 to 10, padded with dashes to visualize the recursion level.
Executing the above in psql prints:
concat
-------------
1
-2
--3
---4
----5
-----6
------7
-------8
--------9
---------10
(10 rows)The complete SQL query in the EmployeeService class contains these same four parts, but just with a bit more noise and different logic to do the recursion. It finds new nodes where the managerId matches the employeeId from the parent node. The query is also:
- Ordering the result set based on the “parent path” so that results will appear in a stable and logical order (without additional Java logic) in the UI.
- Limiting the results set so that we don’t accidentally choke the DB-JVM connection or server memory.
- Passing in additional rules to stop the recursion for certain sub-trees that are closed in the UI (coming back to this soon).
That truly is a complex “little” query, and it would be tempting for a Java developer to execute multiple queries and crunch the data at the service layer. But the value is clear: we are not bothering our DB with more than one single query that returns an easily digestible set of data for the UI layer. We can request more pages on demand if the user scrolls down in the UI.
For a Java developer, the easy part is now to connect this one page of results to the TreeTable component. Although the TreeTable is now getting the data pre-crunched into a logical “pre-order,” it still needs at least two different things:
- A special hierarchy column definition to visualize the hierarchy. This part works like in the official TreeGrid and like any other columns, except that you use
addHierarchyColumnmethod instead ofaddColumn, which is used for normal columns. - The level (or depth) on the hierarchy. This is an integer passed in via “
LevelModel.” In the UI code, it is a single-line lambda expression, taking the value from the DTO (the level column calculated in the SQL query).
For a better UX, there are two more things we want to configure:
- Define a
LeafModelthat controls the visibility of the ▷/▽ symbol before the node that visualizes and controls whether the subtree is displayed. In this example, the amount of subordinates is pulled in via subquery, but returning a boolean in any other way is fine as well. - The final touch comes from allowing the user to control whether the subtree is open. This data needs to be passed for the SQL query for optimal queries. This example uses an OpenModel implementation that keeps all nodes open by default and then passes the explicitly closed items (user clicking the triangle in the UI or custom logic) via the service layer to the SQL query. Depending on your use case, an inverted default or completely custom
OpenModelmay be more appropriate. Alternatively, you can disable the functionality from the UI entirely and use the ▷/▽ symbol only for visualization purposes.
The actual data binding then largely resembles the lazy data binding to a normal Vaadin Grid. TreeTable asks for the needed page using the Query object, from which offset and limit are passed along with the potentially closed subtrees to the service layer. Additionally, there could be, for example, filtering connected to the data binding part.
treeTable.setItems(q ->
service.findAll(
q.getOffset(),
q.getLimit(),
openModel.getClosed()
).stream()
);2. The ltree Data Type in PostgreSQL
The first introduced approach is great in many ways. For example, the table structure is academically correct (fully normalized), CTEs are supported by most databases these days, and mastering CTEs may help you solve other complex RDBMS problems. But the issue with it is the CTE query. They are complex to write and maintain.
An alternative approach is to store additional metadata, making hierarchical queries simpler to write. PostgreSQL features a data type called ltree (label tree) designed for this purpose, equipped with functions and operators for efficient data handling. SQL Server has a somewhat similar type called hierarchyid, and there are likely equivalents in other databases.
As an example, I wrote the exact same example as above, utilizing the PostgreSQL-specific ltree data type. I decided to replace the primary key with ltree and rename that to managerPath, as it also contains the information of all managers the employer has. And as the direct supervisor was also there, the managerId was also removed. The database structure is actually a bit simpler than in the first approach, but from an academic point of view, the data is not perfectly normalized. There is a bit of redundancy within the managerPath. The employees table is now defined like this:
CREATE TABLE employees
(
managerPath ltree PRIMARY KEY,
firstName varchar(30) NOT NULL,
lastName varchar(40) NOT NULL,
title varchar(50) NOT NULL
);If you compare the SQL query built in this branch to the one using CTEs, you’ll quickly see the value of this approach. Even though the query uses non-standard functions and operators, it doesn’t need a multi-page article to explain it. And, the most important thing, this query, in its complete form, easily fits on my 13-inch laptop screen. 🤣
SELECT
e.managerPath,
e.firstName,
e.lastName,
e.title,
(SELECT COUNT(*) FROM employees WHERE subpath(managerPath, 0, -1) = e.managerPath) directReports
FROM employees e
ORDER BY e.managerPath, e.lastName
LIMIT ? OFFSET ?Although this approach makes the actual queries easier to write (and probably also more efficient for the DB), you may regret taking this route if you are modifying the hierarchies a lot in your application. Even with the flexible functions and operators for the ltree data type, you will need way more SQL magic than simply modifying the parentId reference that you could do with the first approach.
The best compromise might be to store the “source of truth” using normal primary and foreign keys and use ltree data type as non-normalized metadata just to simplify your queries. Maintaining the ltree data could be done at your service layer or using database functions and triggers, as suggested in a great article about ltree’s by Cris Farmiloe.
Binding to the UI component works the same as in the first approach. The only bigger difference is passing the level of hierarchy for the TreeTable component. The query doesn’t return the level directly, but the DTO still has the same getLevel method. It counts the level from the number of segments in the ltree value (passed as a String to the Java side):
public Integer getLevel() {
return managerPath.split("\\.").length - 1;
}3. The Non-standard CONNECT BY Luxury from Oracle
Oracle users can solve the “query problem” in a pretty elegant way. The data is stored in a similar intuitive data structure as in the first approach, in a fully normalized manner. But instead of using CTEs in the query, we can use the more intuitive CONNECT BY syntax available in selected commercial databases (IBM DB2 seems to have a similar feature, but I have no experience with that).
In a CONNECT BY query, one must also define the root nodes from which the recursion starts. These are declared with the START WITH clause; in our example, START WITH managerId IS NULL. Connecting the following levels of rows happens with the CONNECT BY PRIOR employeeId = managerId clause, where the left-hand side is from the parent row, and the right-hand side is from the evaluated row. The full query example from the project looks like this:
SELECT
emp.managerId,
emp.employeeId,
emp.firstName,
emp.lastName,
emp.title,
(SELECT COUNT(*) FROM employees WHERE managerId = emp.employeeId) AS directReports,
-- connect by specific pseudo columns, can be handy at UI layer
LEVEL,
CONNECT_BY_ISLEAF,
SYS_CONNECT_BY_PATH(employeeId, '/') path
FROM employees emp
START WITH managerId IS NULL
CONNECT BY PRIOR employeeId = managerId
OFFSET ? ROWS FETCH NEXT ? ROWS ONLYThe CONNECT BY queries are primarily designed for querying hierarchical data (as opposed to CTE queries, which is a general-purpose tool for SQL magic). The data comes out of the query by default in the natural tree order, like one usually wants for human-readable views. Also, a couple of handy meta columns are implicitly available without additional SQL trickery. You will, for example, value LEVEL and CONNECT_BY_ISLEAF columns when visualizing the data in your UI (like when connecting to the TreeTable component).
In general, the CONNECT BY-based SQL query is much easier to read than a similar CTE-based query and does not require any compromises on the table structure. The downside is the proprietary syntax that is only available for some databases.
The data binding to the TreeTable in this option is the same as in the first solution.
Summary
For optimal performance, you can fetch your hierarchical data using a single SQL query, but it is not trivial. Forget JPA, even if you use it to persist or edit data. Remember to fetch the level in the hierarchy and whether the tree node has children. You will need those details at the UI layer. For SQL queries, you have (at least) three possible options:
- CTE query: the most flexible and compatible approach
- The ltree data type in PostgreSQL: the easiest and most readable queries
- CONNECT BY query: the thing you’ll probably use if you can afford Oracle
It depends, as always. I hope my examples help you to pick the best solution for your use case. Check it out via GitHub or share your recipe in the discussion below!