
Large Language Models (LLMs) are amazing tools. We can ask them to do things for us in plain language, and they use their vast knowledge of the world to deliver an answer in an instant.
But when it comes to building AI-powered applications, there's a big problem: LLMs are generic, while our business is not.
In this guide, we'll explore how to build a custom AI agent tailored to your business needs using Java. We'll look at both the theory and practice of integrating AI into enterprise applications, ensuring you have the knowledge to implement these concepts—even if you're new to AI in Java.
The example app we'll be working with is an airline customer support agent for a hypothetical airline, Funnair.
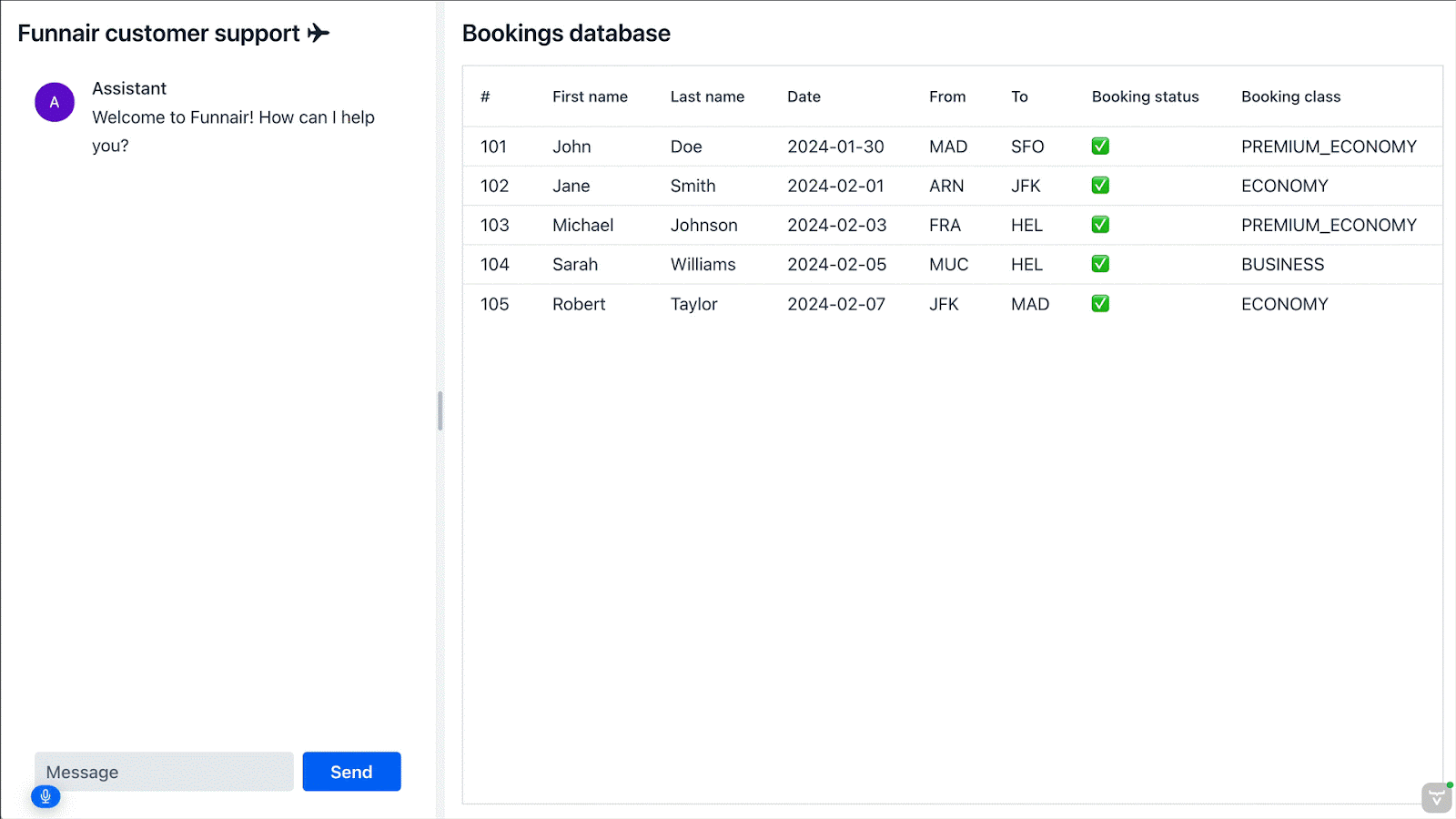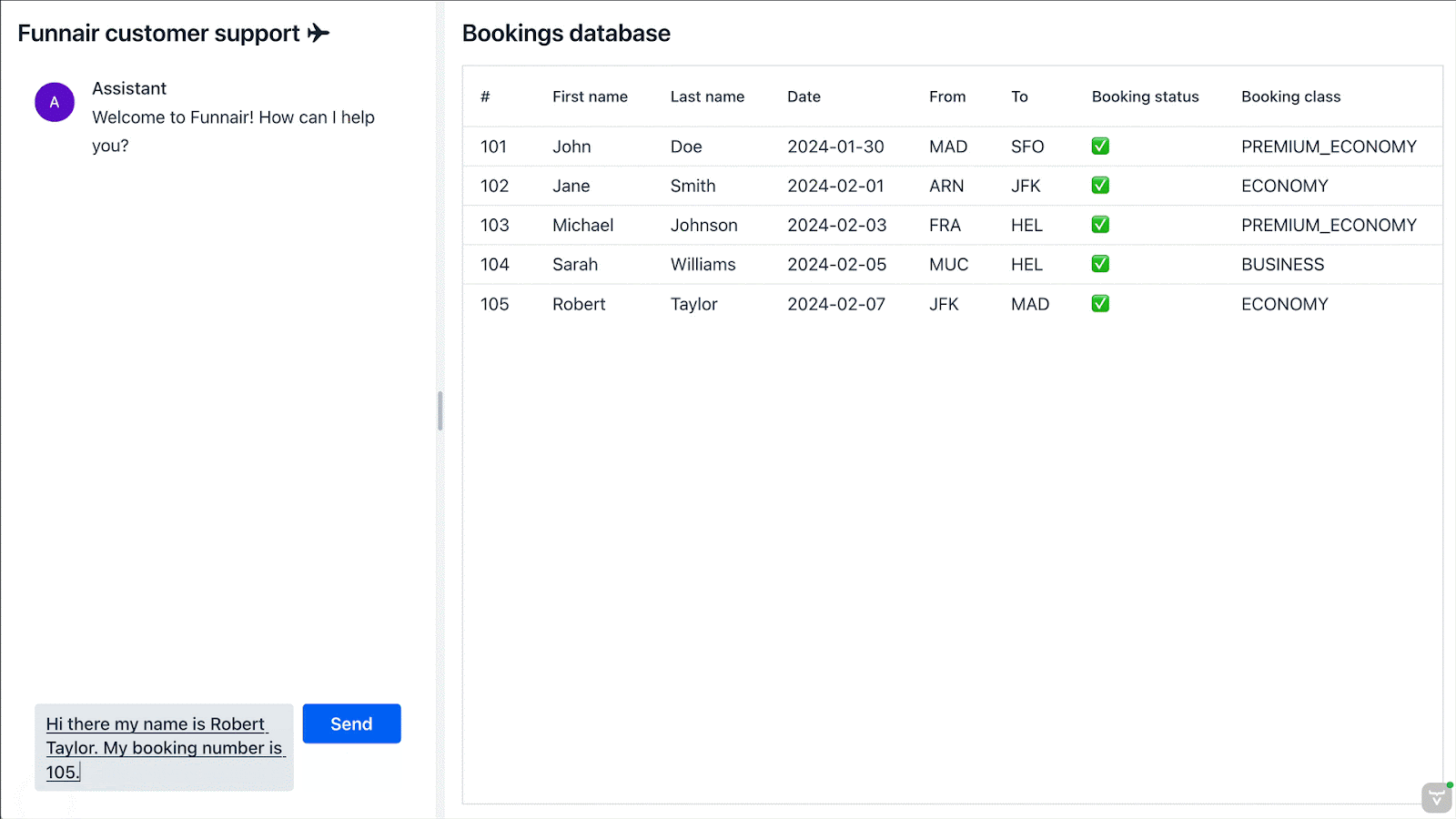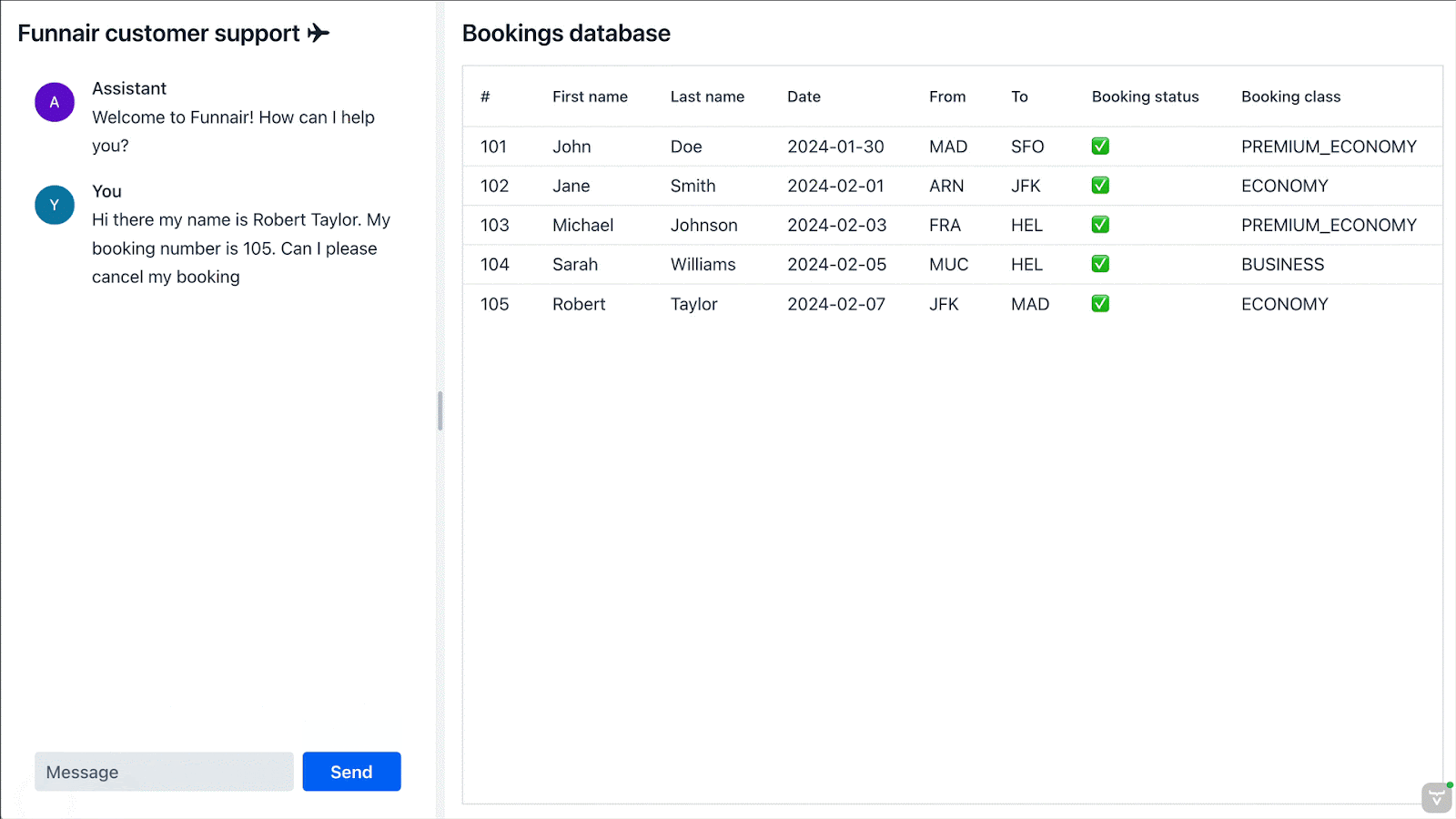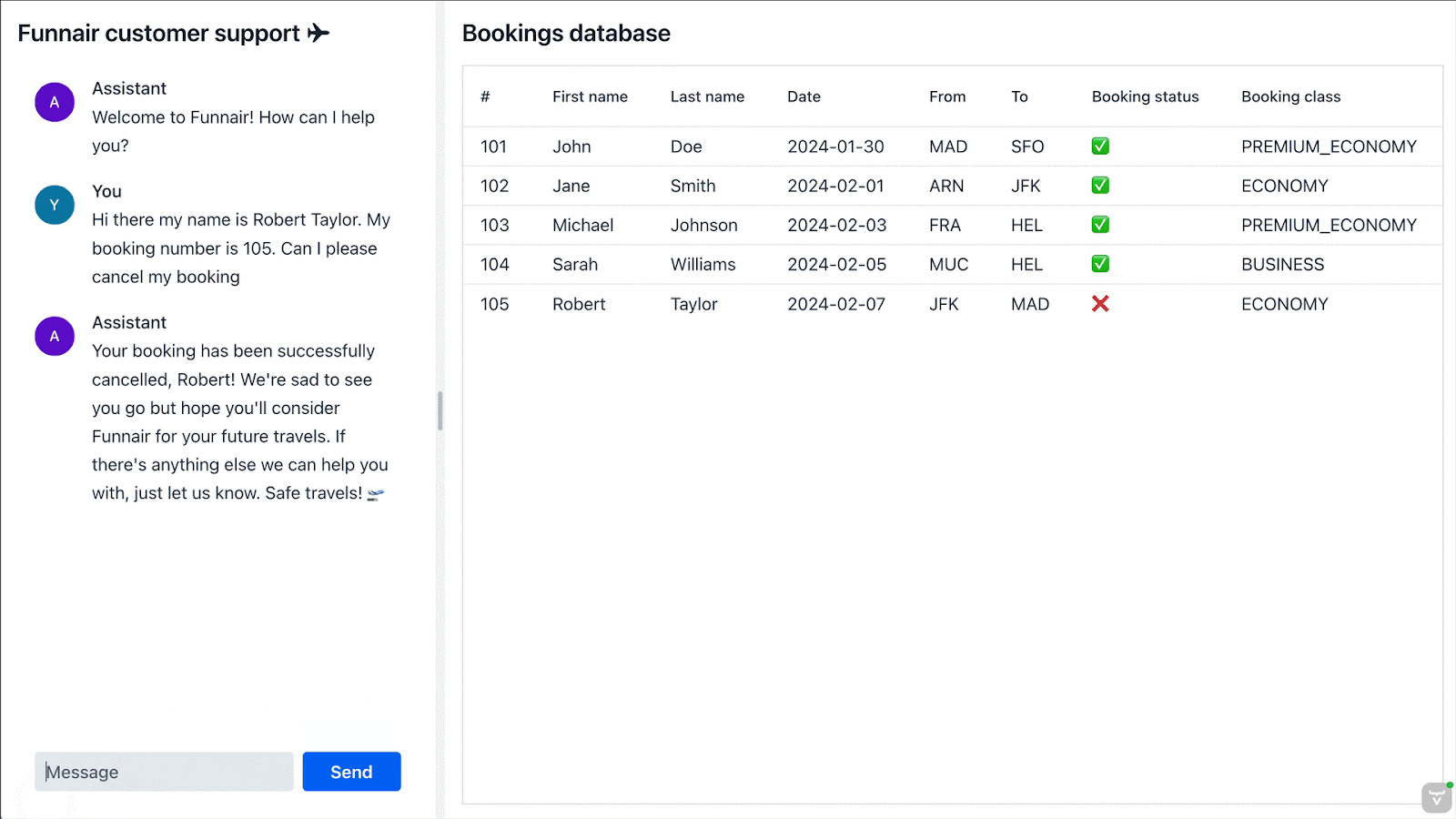
Table of contents
- Introduction
- Tech stack and source code
- Understanding agent autonomy levels
- Building an AI chatbot in Java
- Enhancing the AI with business context using RAG
- Empowering the AI to perform actions
- Summary
- Next steps
Introduction
When building AI-powered applications, we need to bridge the gap between the generic knowledge of LLMs and the specific context of our business. This guide will show you how to create an AI agent that is not only aware of your business context but can also perform actions on your behalf, enhancing user interactions and automating tasks.
If you prefer, you can follow along with the tutorial in the YouTube video linked below.
Tech stack and source code
We'll use the following technologies:
- UI: Vaadin Hilla
- Backend: Spring Boot
- Frontend: React
- AI Coordination: LangChain4j
The complete source code is available on GitHub. The repository includes implementations using LangChain4j, Spring AI, and Semantic Kernel in separate branches for comparison.
Understanding agent autonomy levels
Before integrating AI into our application, it's crucial to decide the level of autonomy we want to grant the AI agent. AI agents can be categorized based on how much control they have:
- Chatbot: Provides answers based solely on pre-trained data.
- Retrieval-Augmented Generation (RAG): Uses pre-trained data plus additional context we supply.
- Copilot: Has access to specific tools and can perform limited actions.
- Fully autonomous: Operates independently, performing tasks without human intervention.
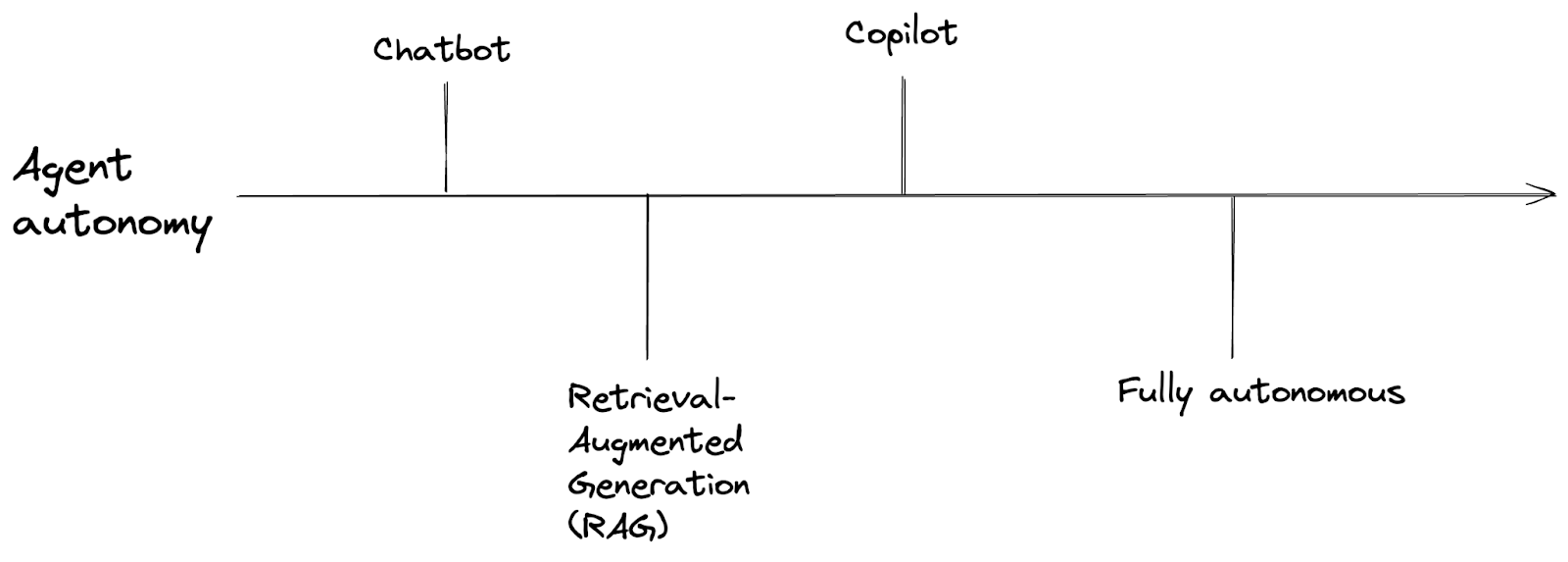
For most enterprise applications, RAG and Copilot levels are ideal. They allow the AI to be helpful and context-aware while ensuring we maintain control over critical operations.
Building an AI chatbot in Java
Let's start by building a basic AI chatbot using LangChain4j. We'll integrate it with a Spring Boot backend and a React frontend.
Setting up LangChain4j in Spring Boot
Add the following dependencies to your pom.xml:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>${langchain4j.version}</version>
</dependency>Configure LangChain4j in application.properties:
langchain4j.open-ai.streaming-chat-model.api-key=${OPENAI_API_KEY}
langchain4j.open-ai.streaming-chat-model.model-name=gpt-4
langchain4j.open-ai.streaming-chat-model.temperature=0
langchain4j.open-ai.embedding-model.api-key=${OPENAI_API_KEY}
langchain4j.open-ai.streaming-chat-model.strict-tools=trueNote: Replace ${OPENAI_API_KEY} with your actual OpenAI API key, preferably set as an environment variable to avoid exposing it in version control.
Defining the LLM interface
LangChain4j allows you to define an interface annotated with @AiService. This interface represents the AI assistant:
@AiService
public interface Assistant {
@SystemMessage("""
You are a customer chat support agent of an airline named "Funnair".
Respond in a friendly, helpful, and joyful manner.
You are interacting with customers through an online chat system.
Before providing information about a booking or cancelling a booking,
you MUST ensure you have the following information from the user:
booking number, customer first name, and last name.
Before changing a booking, you MUST ensure it is permitted by the terms.
If there is a charge for the change, you MUST ask the user to consent before proceeding.
Today is .
""")
Flux<String> chat(@MemoryId String chatId, @UserMessage String userMessage);
}@SystemMessage: Provides instructions to the AI about its role and behavior.@MemoryId: Associates the conversation with a specific chat session.@UserMessage: Represents the user's input.
Streaming responses to the UI
In the AssistantService, we handle the AI's response and stream it to the frontend:
@BrowserCallable
@AnonymousAllowed
public class AssistantService {
private final Assistant assistant;
public AssistantService(Assistant assistant) {
this.assistant = assistant;
}
public Flux<String> chat(String chatId, String userMessage) {
return assistant.chat(chatId, userMessage);
}
}Flux<String>: A reactive stream that emits the AI's response tokens.- Frontend consumption: The React frontend subscribes to this stream and updates the UI as new tokens arrive.
On the React side, we maintain the conversation state and handle incoming messages:
const [working, setWorking] = useState(false);
const [messages, setMessages] = useState<MessageItem[]>([{
role: 'assistant',
content: 'Welcome to Funnair! How can I help you?'
}]);
async function sendMessage(message: string) {
setWorking(true);
addMessage({
role: 'user',
content: message
});
let first = true;
AssistantService.chat(chatId, message)
.onNext(token => {
if (first && token) {
addMessage({
role: 'assistant',
content: token
});
first = false;
} else {
appendToLatestMessage(token);
}
})
.onError(() => setWorking(false))
.onComplete(() => setWorking(false));
}
function addMessage(message: MessageItem) {
setMessages(messages => [...messages, message]);
}
function appendToLatestMessage(chunk: string) {
setMessages(messages => {
const latestMessage = messages[messages.length - 1];
latestMessage.content += chunk;
return [...messages.slice(0, -1), latestMessage];
});
}We use the Vaadin MessageList, MessageInput, and Grid components to build out the UI, binding them to the state:
<SplitLayout className="h-full">
<div className="flex flex-col gap-m p-m box-border h-full" style=>
<h3>Funnair support</h3>
<MessageList messages={messages} className="flex-grow overflow-scroll"/>
<MessageInput onSubmit={e => sendMessage(e.detail.value)} className="px-0"/>
</div>
<div className="flex flex-col gap-m p-m box-border" style=>
<h3>Bookings database</h3>
<Grid items={bookings} className="flex-shrink-0">
<GridColumn path="bookingNumber" autoWidth header="#"/>
<GridColumn path="firstName" autoWidth/>
<GridColumn path="lastName" autoWidth/>
<GridColumn path="date" autoWidth/>
<GridColumn path="from" autoWidth/>
<GridColumn path="to" autoWidth/>
<GridColumn path="bookingStatus" autoWidth header="Status">
{({item}) => item.bookingStatus === "CONFIRMED" ? "✅" : "❌"}
</GridColumn>
<GridColumn path="bookingClass" autoWidth/>
</Grid>
</div>
</SplitLayout>Configuring chat memory
To maintain context across the conversation, we need to store chat history. We configure a ChatMemoryProvider bean:
@Configuration
public class LangChain4jConfig {
@Bean
ChatMemoryProvider chatMemoryProvider(Tokenizer tokenizer) {
return chatId -> TokenWindowChatMemory.withMaxTokens(1000, tokenizer);
}
}This configuration retains up to 1,000 tokens of conversation history per chat session, ensuring the AI has the necessary context for each response.
Enhancing the AI with business context using RAG
To make the AI agent truly useful, we need to provide it with specific business knowledge, such as policies or FAQs. We achieve this using Retrieval-Augmented Generation (RAG).
Understanding vector embeddings
Before we can retrieve relevant information, we need to understand how vector embeddings work.
Vector embeddings are numerical representations of text that capture semantic meaning. They allow us to measure how similar two pieces of text are in terms of their meaning.
Let's use an analogy with color representation to understand this concept better.
- RGB color model: In digital graphics, colors are represented using the RGB model, where each color is a combination of Red, Green, and Blue values. Each color can be represented as a vector
[R, G, B]. - Similarity measurement: Two colors are similar if their RGB values are close to each other. For example,
[255, 0, 0](pure red) is more similar to[200, 0, 0](dark red) than to[0, 255, 0](green).
Similarly, vector embeddings represent text in a high-dimensional space where the distance between vectors indicates semantic similarity.
- Text embedding: A sentence like "How do I cancel my flight?" is converted into a vector of, say, 768 dimensions.
- Semantic similarity: If another text, "What's the process to cancel a booking?", is converted into a vector close to the first one, they are considered semantically similar.
Ingesting documents into a vector database
To enable the AI to retrieve relevant business information, we process our documents and store them in a vector database.
Steps:
- Split documents: Break down large documents into smaller, manageable sections.
- Generate embeddings: Convert each text section into a vector embedding using an embedding model.
- Store in vector database: Save the embeddings along with the original text and any metadata.

Here's how you can implement this in Java using LangChain4j:
@Bean
EmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
@Bean
ApplicationRunner ingestDocs(
EmbeddingModel embeddingModel,
EmbeddingStore<TextSegment> embeddingStore,
Tokenizer tokenizer,
@Value("classpath:terms-of-service.txt") Resource termsOfService
) {
return args -> {
var doc = FileSystemDocumentLoader.loadDocument(termsOfService.getFile().toPath());
var ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(50, 0, tokenizer))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(doc);
};
}EmbeddingStoreIngestor: Handles splitting the document, generating embeddings, and storing them.DocumentSplitters.recursive(50, 0, tokenizer): Splits the document into segments of up to 50 tokens.
Augmenting AI responses with retrieved information
When the AI receives a query, we retrieve relevant information from the vector database to include in the prompt. This ensures the AI's responses are accurate and based on your business data.
Retrieval process:
- Embed the query: Convert the user's query into a vector embedding using the same embedding model used for processing the documents.
- Find similar embeddings: Search the vector database for embeddings similar to the query embedding.
- Retrieve relevant text: Fetch the original text associated with the similar embeddings.
- Augment the prompt: Include the retrieved text in the AI's prompt for generating the response.
Implementation:
@Bean
ContentRetriever contentRetriever(
EmbeddingStore<TextSegment> embeddingStore,
EmbeddingModel embeddingModel
) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.6)
.build();
}maxResults: Maximum number of relevant documents to retrieve.minScore: Minimum similarity score for retrieved documents.
By augmenting the AI's prompt with business-specific information, we ensure that responses are accurate and tailored to our policies.
Example:
- User query: "Can I cancel my flight?"
- Retrieved text: "According to our terms, flights can be canceled up to 24 hours before departure."
- AI response: "Yes, you can cancel your flight up to 24 hours before departure as per our policy."
Empowering the AI to perform actions
To elevate the AI from a passive assistant to an active agent, we allow it to perform specific actions through defined functions.
Defining tools and functions
We annotate methods with @Tool to expose them to the AI:
@Component
public class BookingTools {
private final FlightService service;
public BookingTools(FlightService service) {
this.service = service;
}
@Tool("""
Retrieves booking details such as flight date, status, and airports.
""")
public BookingDetails getBookingDetails(String bookingNumber, String firstName, String lastName) {
return service.getBookingDetails(bookingNumber, firstName, lastName);
}
@Tool("""
Modifies an existing booking, including flight date and airports.
""")
public void changeBooking(String bookingNumber, String firstName, String lastName,
LocalDate newFlightDate, String newDepartureAirport, String newArrivalAirport) {
service.changeBooking(bookingNumber, firstName, lastName, newFlightDate, newDepartureAirport, newArrivalAirport);
}
@Tool("Cancels an existing booking.")
public void cancelBooking(String bookingNumber, String firstName, String lastName) {
service.cancelBooking(bookingNumber, firstName, lastName);
}
}- Annotations: Provide descriptions that help the AI understand when and how to use these tools.
- Security considerations: Ensure that appropriate validations and permissions are in place before performing any actions.
Integrating with Spring Boot functions
By integrating these tools with your Spring Boot application, you allow the AI to:
- Fetch data: Retrieve booking details or other information.
- Modify data: Change or cancel bookings securely.
- Interact dynamically: Provide real-time assistance to users.
This transforms the AI agent into a Copilot that can assist users in accomplishing tasks within your application.
Example Interaction:
- User: "I need to change my flight date."
- AI: "Sure, could you please provide your booking number, first name, and last name?"
- User: "Booking number is ABC123, John Doe."
- AI: "Your current flight is on October 15th from NYC to LA. What date would you like to change it to?"
- User: "Please change it to October 20th."
- AI: Calls
changeBookingmethod to update the booking. - AI: "Your flight has been changed to October 20th. Is there anything else I can assist you with?"
Summary
In this guide, we've walked through building a custom AI agent in Java that:
- Interacts naturally: Communicates with users in plain language.
- Maintains context: Remembers conversation history for coherent interactions.
- Is business-aware: Uses Retrieval-Augmented Generation to provide accurate, context-specific responses.
- Performs actions: Executes functions within your application to assist users.
By leveraging LangChain4j, Spring Boot, and Vaadin Hilla, we've created an AI agent that enhances user experience while maintaining control over its operations.
Next steps
Integrating AI into your Java applications doesn't have to be daunting. With the right tools and approach, you can build intelligent agents that are both powerful and aligned with your business needs.
- Explore the full source code on GitHub and try the application yourself.
- Experiment with different AI models supported by LangChain4j.
- Extend the AI agent with additional tools and business logic.